数据结构与算法 - 散列表
在之前介绍了二分查找、利用跳表进行查找,在查找效率上都非常高,但是它们有个共同的特点,就是都是基于元素比较的查找。本节介绍一种新的查找方式-散列表,又称哈希表。
散列表的底层依赖于数组,算是数组概念的推广,正因为数组支持直接寻址,能够在O(1)时间复杂度内找到目标,才有了散列表高效的查找。
考虑这样一个例子,要记录一个考场内所有考生的信息,如果按照座位号进行存储的话比较容易,直接使用数组来存储即可;如果要求按照身份证号来查找,那么应该如何进行存储,才能实现高效的查找呢,一种可行的办法是采用身份证号的后几位数字,比如后3位,当通过身份证号进行查找时,只需要截取后几位数,作为数组的索引来读取数组中的数据。
这种实现方式就是散列思想的应用,其中身份证号叫做键;将关键字转为数组下表的方法叫做散列函数;散列函数计算到的值叫做散列值。
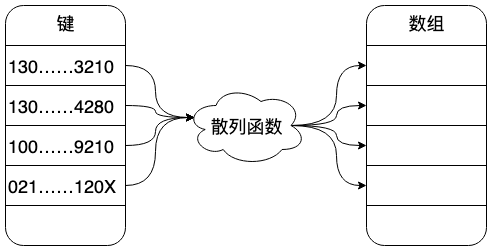
上面例子的散列函数形式大致如下:
1 | int HashCode(string id) |
相关概念
在继续介绍下面内容之前,先介绍几个概念:
槽/桶:散列表是依赖于数组的结构,数组中的每一个元素称为一个槽/桶,可以通过散列值计算出其数组下标。
装载因子:一个衡量数组使用程度的指标,常用$\alpha$表示,其值:$\alpha$ = 散列表中元素数 / 槽数。
散列函数
散列表的核心在于散列函数的设计,如果散列函数设计不当,可能会造成散列表性能退化到O(n),一个优秀的散列函数应该满足下面三个条件:
- 一致性 - 键相等,散列值必须相等
- 高效性 - 计算简单,复杂度不能太高
- 均匀性 - 均匀的分布所有的键
一致性其实分为两个方面,如果键相等,则散列值应该相等;如果键不相等,则散列值应该不相等,但是这几乎是不可能的,这种键不相等,但是散列值相等的情况,称为散列冲突。
高效性比较容易解释,散列函数如果复杂度很高,会降低散列表的效率。
均匀性就是保证所有的键能够均匀的散列到整个范围中,保证均匀性最好的办法就是保证键的每一位都在散列函数中起到了相同的作用,实现散列函数最常见的错误就是忽略了键的高位,很遗憾的是,没有什么好的方法来测试所有的键是否被均匀的散列。
在介绍了散列函数的几个特点之后,下面介绍几个具体实现散列函数的方法:乘法散列法、除法散列法、全域散列法。
除法散列法
除法散列法的核心思想是将键 k 除以 m 求余:
除法散列法的重点在于 m 的选择,这里需要注意以下几点:
- 不能是$2^p$,如果 $m = 2^p$,相等于散列函数只保留了 p 个最低位,忽略了高位的计算,这与之前提到的均匀性要求是违背的。
- 当 k 是按基数$2^p$表示的字符串时,$m=2^p-1$也是非常差的选择,因为任意置换字符串中字符位置,不会改变散列值。
通常可以选择一个不太接近$2^p$的素数,例如要使用散列表来存储大约包含2000个元素的字符串,如果我们能够承受平均每次查找3个元素(由于散列冲突造成),那么可以选择$2000 / 3 \approx {667}$,距离该值相近的2的整数幂为 512、1024,可选择的素数比较多:710、709、719、727……
假定选择了727,那么基数为 x 和 x+727的散列值是相同的,比如基数为315、1042、1769的键对应的散列值都是 315,这就是发生了散列冲突,需要在这冲突的元素中,找到要查找的目标。
乘法散列法
乘法散列法包含以下两步骤来处理键 k:
- 将 k 乘以小数 A (0<A<1),然后提取结果的小数部分。
- 将上一步得到的小数部分,乘以 m,并将结果向下取整。
这里 m 的选择并不是特别重要,一般 $m = 2^p$;A 的选取比较有讲究,一般 $A = s / 2^w$,其中 w 为计算机的字长,Knuth 认为 $A=\sqrt{5}-1 / 2 \approx 0.618$。
全域散列法
在某些极端情况下,恶意的攻击者可能会针对你的散列函数,精心设计一些冲突数据,使得散列表查询的时间复杂度从O(1)迅速退化为O(n),比如有10万条记录,效率下降将近10万倍,正常情况下散列表查询只需要 0.1 秒,退化后需呀 1 万秒,消耗大量的资源来进行散列表的查找,而不能处理其他用户请求,达到DDos 攻击的目的,这就是散列表冲突攻击的基本原理。
因此,在设计散列函数时,除了要考虑键的均匀散列,还要具备一定的随机性,不管对手选择怎样的键,都能够均匀的进行处理。
全域散列法是利用一组精心设计的散列函数(这组散列函数称为函数簇),每次散列时,随机从中选取一个作为散列函数,这样就会极大的降低复杂度退化的可能性。
那么这组散列函数如何设计呢,这里直接给出结果,相关的证明可以参考算法导论中的详细介绍,首先给出散列函数的原型,然后逐一解释其中参数的含义:
- P 是一个足够大的素数
- A 是 [1,P-1] 之间的整数
- B 是 [0,P-1] 之间的整数
- M 是散列表的槽数
函数簇定义为:
散列冲突
即便是 md5 这种哈希算法,都会存在散列冲突,常用的解决办法有两种:开放寻址法、链接法。
开放寻址法
开放寻址法的思想是在遇到散列冲突之后,接着向后进行探查,直到找到空闲位置。探查的方式包含以下几种:
- 线性探查法
- 二次探查法
- 双重探查法
线性探查法
线性探查法的思路非常简单,以散列表的查找为例,首先根据键找到散列表相应的元素 Q,如果不是要查找目标,接着查找下一个元素,依次探查到最后,再从头探查,直到元素Q,用图表示如下:
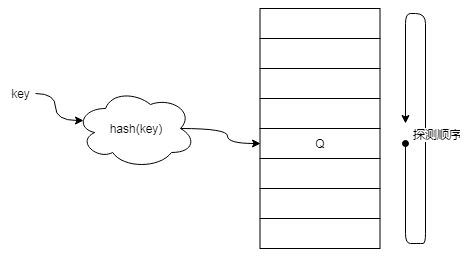
线性探查采用的散列函数如下:
其中hash 是一个普通的散列函数,线性探查过程如下:
- 首先检查 hash(k) 是否为探查目标,找到了,或者为空,则结束查找,否则继续。
- 探查 Hash(k,1) - Hash(k,m-1)
- 如果没有探查到,则说明目标不在散列表中
从上面过程可以看出,最坏的探查情况是要遍历整个散列表,并且随着散列表的数据增长,查找时间也会不断的增加。
二次探查法
二次探查法与线性探查法类似,只不过线性探查法的探查步长为 1,而二次探查法的步长是成平方递增的,它的散列函数如下:
其中$c_1$、$c_2$为正整数。
双重探查法
双重探查法是开放寻址法最好的探查方法之一,因为它产生的散列排布具备随机选择排布特性,它的散列函数如下:
为了能够查找整个散列表,$h_2(k)$必须与 m 互素,实现两数互素的办法有很多,这里只介绍两种
- 让 m 取2的整数次幂,$h_2(k)$总是返回奇数。(2的幂和任何奇数互素)
- 让 m 为素数,$h_2(k)$的返回值总是比 m 略小。(两个数中较大的为素数,则两数互素)
链接法
在链接法中,将所有散列值相同的元素,通过结点指针链接起来,散列槽中存放这头结点的指针。
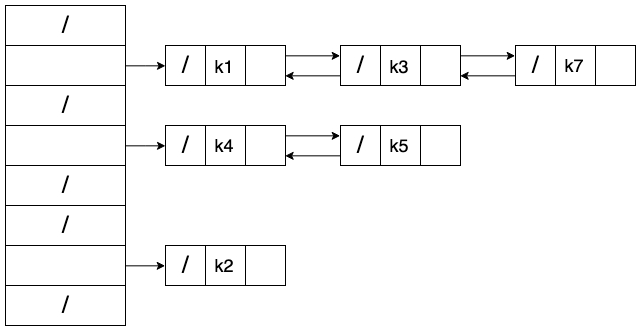
链接法散列性能分析
以散列表的查询为例,分析一下采用链接法的散列表的性能,给定一个元素数量为 n,槽数为 m 的散列表 T,定义 T 的装载因子$\alpha = n / m$,表示一个链平均存储元素数,值越大说明元素越多,空闲位置越少,散列冲突概率越大,下面借用此概念来做性能分析。
- 最坏的情况下,所有 n 个元素都在一个槽中,此时散列表退化为普通链表,查询时间复杂度变成 O(n)
- 平均情况依赖于元素的平均分布情况,一次不成功的查找的平均时间为$\Theta(1+\alpha)$
- 在所有元素平均分布的情况下,一次成功查找所需的平均时间为$\Theta(1+\alpha)$
开放寻址法 vs 链接法
开放寻址法优点:
- 所有元素存储在数组中,能够利用 CPU 缓存加快查询速度。
- 数组结构序列化起来比较简单
开放寻址法缺点:
- 对于散列冲突的元素,查询、删除时间复杂度较高。
- 装载因子不能太大,太大的话,散列表退化几率将会增加。
综上,当数据量比较小的情况下,适合采用开放寻址方式。
链接法的优点:
- 内存利用率比较高。
- 对于散列冲突的元素,查询、删除等操作时间复杂度较低。
- 装载因子可以较大,虽然会增加链表的长度,但是在效率上仍然是可以接受的。
链接法的缺点:
- 由于使用链表,需要额外的指针空间,内存会有额外消耗。
- 由于使用链表,内存空间是不连续的,不利于 CPU 缓存。
综上:链接法适用于数据量非常大的情况,相比与开放寻址法,链接法更加灵活,可优化空间比较大(对链表的优化)。
代码实现
在介绍玩一些理论知识之后,看一下实际的散列表应该如何实现,这里采用链接法处理散列冲突,代码参考 C# 的 Dictionary。
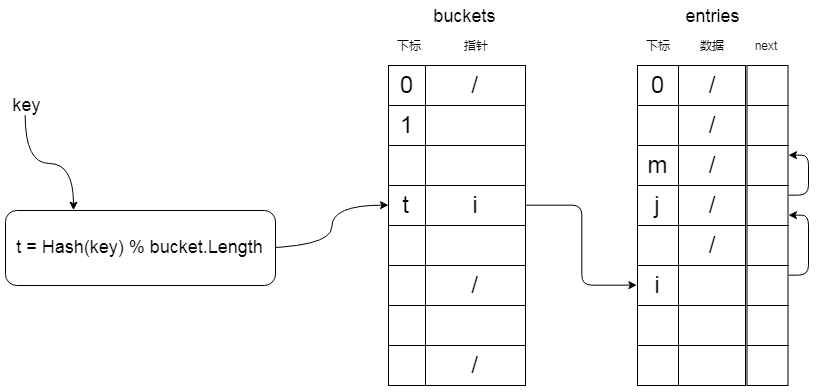
对上图稍作解释:
- buckets 是散列表的槽,int类型数组,存储着指向链表的头结点的指针。
- entries 是散列元素数组,Entry类型,Entry.next 指向链接的下一个结点,-1 表示为最后一个结点。
插入的实现
插入的核心流程是:
- 获取对象的散列值(hashCode),根据散列值计算出槽位(targetBucket)。
- 根据槽位在 entries 数组找到元素(链头),根据 next 指针遍历整条链,如果某个结点的键值与要插入的键值相等,说明已经存在,直接返回。
- 如果不在散列表中则进行插入,将新 Entry 添加到 entries 数组,并将 Entry.next 指向链头,更新散列表的槽,使之指向新的链头。
代码如下:
1 | private void Insert(TKey key, TValue value) |
删除的实现
删除元素的流程如下:
- 获取对象的散列值(hashCode),根据散列值计算出槽位(targetBucket)。
- 根据槽位在 buckets 数组中找到链头索引,根据链头遍历整条链,检查每个结点是否为要删除的结点。
- 在删除时,要注意维护好整条链的链接,以及更新 buckets 槽中的链头指针。
代码如下:
1 | public bool Remove(TKey key) |
查找的实现
在明白插入和删除之后,插入就很简单了,这里就不实现了,详细的代码实现可以参考这里。
动态扩容
上面虽然使用了链接法,但是没有使用链表,而是采用 Entry 数组来模拟链表功能,在这里 Entry.next 是一个指向 entries 的指针,它有两方面作用:
- 当 Entry 存储着数据时,next 指向下一个散列冲突结点。
- 当 Entry 可利用时(即没有存储数据),next 指向下一个空闲的节点。
freeList 字段记录着闲置链表的头结点索引,当值为 -1 时表示没有闲置的节点。当需要向 entries 中插入数据时,首先检查闲置链表是否为空,如果为空,再从 entries 中分配。
最后在啰嗦一句 C# 的 Dictionary