数据结构与算法 - 跳表
在前面介绍了二分查找,它是一种时间复杂度为$O(\log{n})$的高效查询算法,因为它依赖于有序数组,因此存在一些局限性。我们知道链表不要求连续内存,但是它不支持随机访问,比如在链表 L 中,如果需要查找第 k 个元素,就需要从头开始挨个结点进行查找,那么应该如何提高这种有序链表查找效率呢,基于这个出发点,出现了跳表这种数据结构,
在介绍跳表之前,首先思考一下,对于一个有序链表,如何才能提高它的查找效率呢?
参考前面的二分查找思想,是不是同样可以将数据的中点提取出来,这样不就可以直接访问到中点了?至于结果行不行的通,先看下如果采用这种方法时的查找过程,见下图。
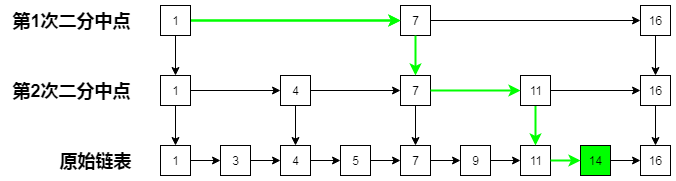
可以看出,如果我们挨个遍历的的话需要遍历8个元素,通过提取二分中点来查询则需要经过6个元素,虽然两者相差不多,但是对于规模非常大的数据来说,两者的差距也越大。
跳表是什么
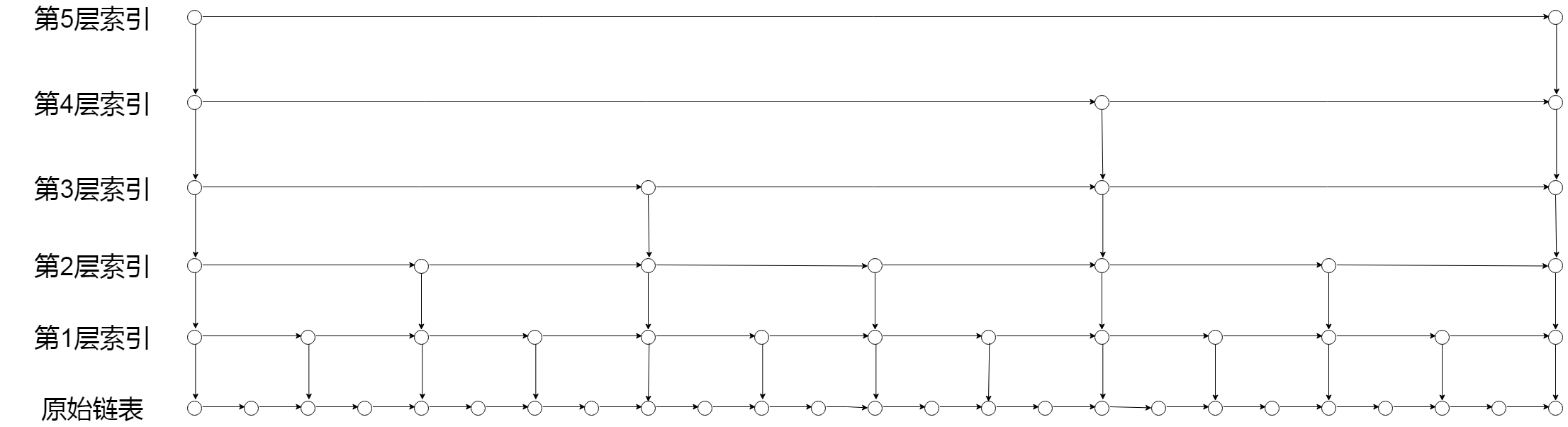
跳表的思想和上面所说的比较类似,都是通过提取多层索引来提高元素访问效率,但是跳表是通过间隔 n 个元素作提取,而非提取中间点,如下图:
跳表的性能
首先分析跳表的查询的时间复杂度:
- 根据上图可以看出第1层索引的结点个数为 ${n}/{2^1}$,第2层结点个数为${n}/{2^2}$,依次类推第k层的结点个数为$n/{2^k}$。
- 假设跳表有 h 层索引,最高层只有首尾两个结点,即$n/{2^h}=2$,可以得到$h=\log_2{n}-1$,加上原链表本身一共 $\log_2{n}$ 层。
- 那么每层的复杂度是多少呢?即要遍历多少结点,因为经过上层的索引之后,就能够锁定查找的目标在下层的范围,所以每层最多遍历3个结点。
- 因此通过跳表查找元素的时间复杂度为:$T(n)= O(3\log_2{n}) = O(\log_2{n})$。
跳表的空间复杂度:
通过上面计算,知道第k层的节点个数为$n/{2^k}$,根据下面的几何级数求和公式,(h=$\log_2n-1$)可以计算出总结点个数为:n-2,因此跳表的空间复杂度为O(n)。
这里需要强调的是,虽然空间复杂度为O(n),但是索引结点只存储结点指针,并不存储数据内容,在实际开发中,链表存储的数据内容通常是非常大的,此时就不必太强调空间复杂度。
跳表的实现
与链表不同,跳表的节点还需要存储它的索引信息,下面是节点类设计:
1 | // 跳表类型 |
SkipList 表示跳表数据类型,包含头结点引用和尾节点引用。
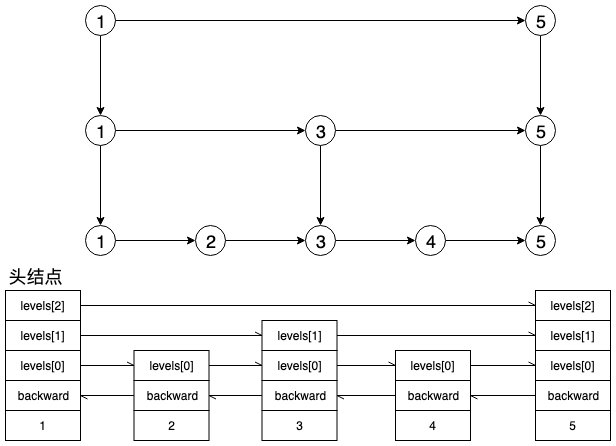
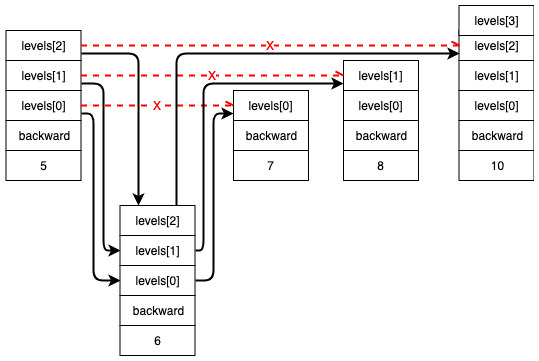
SkipListNode 表示链表的节点,每个节点都可能包含多层索引和后退节点,索引用 SkipLevel 表示,其中 forward 表示节点在该层跳转的节点,可以通过下图来帮助理解。
查找操作
查找应该从头结点的最顶层索引开始,递归的遍历前进节点,因为跳表的元素都是有序排序的,所以当节点的前进节点大于要查找的元素时,就需要进入下层索引进行查找,当所有层都遍历完成之后,得到了一个边界节点,需要进一步比较确认,它的前进节点是不是要查找的元素,详细代码如下:
1 | // 查找指定节点 |
插入操作
向跳表中插入元素时,必须同时更新索引,如果不更新,就可能造成两个索引节点之间节点过多,查询时间复杂度也会退化为O(n)。
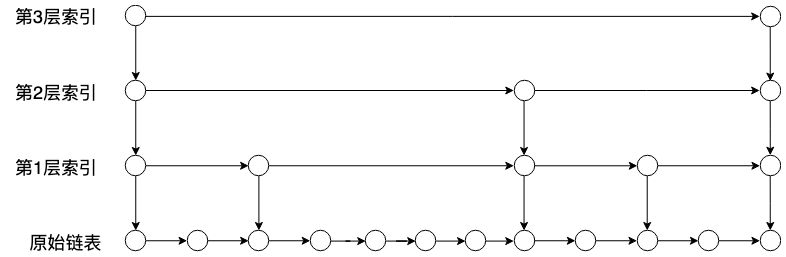
为了解决该问题,最直接的办法就是每次插入新元素之后,把插入位置之后的索引重新进行计算,但是这样在效率上就会比较低。有一种比较折中的办法,既能够很大程度的降低跳表退化概率,同时在插入效率上也比较高,该方法是在插入时,随机的选取一个层,在该层和之下层中插入索引结点。
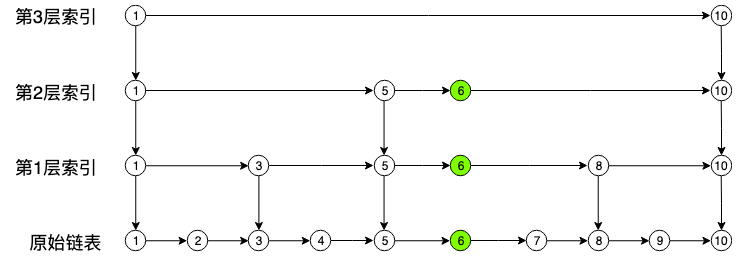
结合上图理解一下跳表的插入步骤:
- 随机选取层索引,下面更新选取层和其下的所有层,上面是[0,2]。
- 找到各层需要插入的位置,上面各层都是结点5。
- 更新各层的索引的前进结点,在上图中,是将各层结点5的前进结点指向新结点6,将6的前进节点指向结点5之前的前进结点。
- 更新后退结点。
结点属性的变化关系如下图:
代码实现如下:
1 | public void Insert(T t) |
在选择索引层时使用了随机算法,为了保证随机结果能够均匀分布,将随机算法实现如下:
1 | private int RandomLevel() |
删除操作
在理解了跳表的插入过程之后,删除操作也就很好理解了,除了要删除源链表的结点之外,还要删除该节点对应的索引节点,代码如下:
1 | public void Remove(T t) |
最后
上面介绍了跳表一些常用操作和实现,相对于之后要介绍的二叉平衡树要简单,在查询、插入等操作上效率也非常高。在开源K-V
数据库 Redis 中就使用了跳表,感兴趣的可以学习一下,最后完整的代码在这里。